Extending Context Length for Large Language Models (LLMs)
If a user’s conversation with ChatGPT exceeds the context window, its performance will sharply decline. Increasing context length has become one of the primary efforts for tech companies to improve models and gain a competitive edge.
Recently, Google released a new paper introducing a new technology that enables large language models to handle unlimited-length contexts. The new paper claims to give Large Language Models (LLMs) the ability to process text of infinite length. The paper introduces “Infinite Attention,” a technique that configures language models to handle unlimited-length text by expanding the “context window” while keeping memory and computational requirements constant.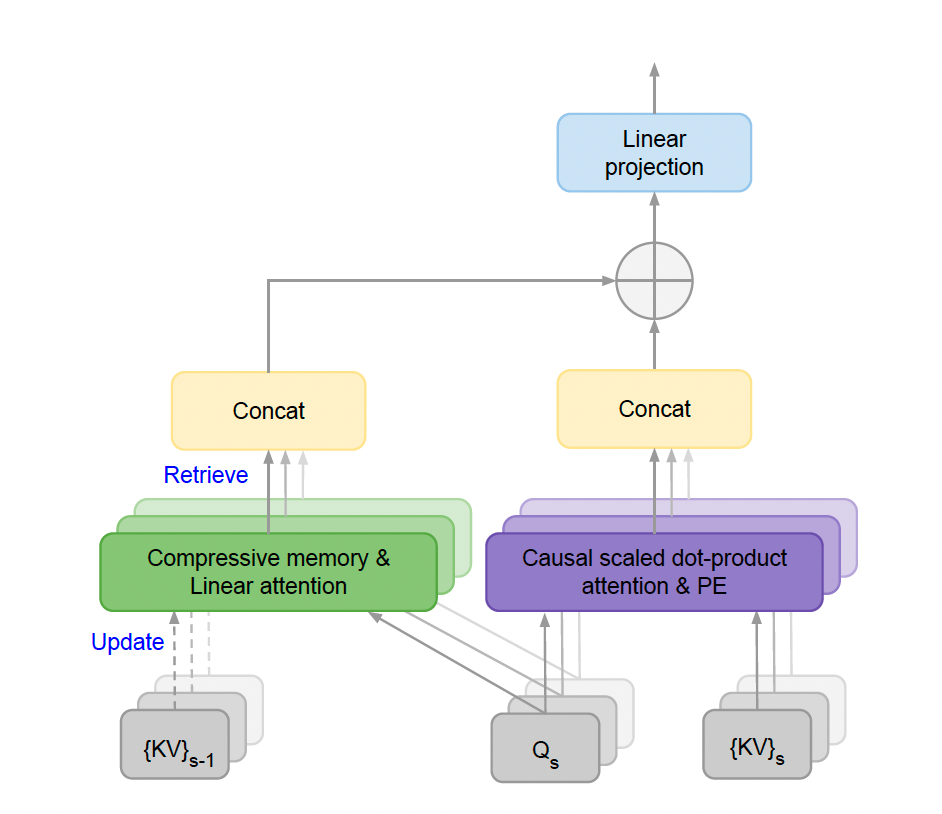
Experiments reported by the Google research team show that models using infinite attention can maintain their quality even with over a million tokens, without requiring additional memory. The same trend theoretically continues to larger lengths.

Infinite Attention
The Transformer, a deep learning architecture used in LLMs, has “quadratic complexity” in memory usage and computation time. This means that the memory and time required to process data with Transformer grow exponentially with the input data size. For example, expanding the input size from 1,000 tokens to 2,000 tokens not only doubles the memory and computation time required to process the input but also quadruples it.
This quadratic relationship is due to the self-attention mechanism in Transformers, which compares each element in the input sequence with every other element.
In recent years, researchers have developed various techniques to reduce the cost of extending context lengths in LLMs. This paper describes infinite attention as “long-range compressed memory and local causal attention, used to effectively model long- and short-term contextual dependencies.”

This means that Infini-attention retains the classic attention mechanism in Transformer blocks and adds a “compressed memory” module to handle extended inputs. Once the input exceeds its context length, the model stores old attention states in a compressed memory component, which maintains a constant number of memory parameters to improve computational efficiency. To compute the final output, Infini-attention aggregates compressed memory and local attention contexts.
Researchers state, “Such subtle but crucial modifications to the Transformer attention layer allow existing LLMs to naturally extend to infinite lengths of context through continuous pre-training and fine-tuning.”
Performance of the Infinite Attention Architecture
Researchers tested the Infini-attention Transformer in benchmark tests on extremely long input sequences. In long-context language modeling, Infini-attention maintains low perplexity scores (a measure of model consistency) while requiring 114 times the memory, outperforming other long-context Transformer models.

In the “key retrieval” test, Infini-attention is able to return random numbers from long texts with up to a million tokens inserted. It outperforms other long-context techniques in summarizing tasks with up to 500,000 tokens.
The paper states that the tests were conducted on LLMs with 1 billion and 8 billion parameters. Google has not released models or code, so other researchers cannot verify the results. However, the reported results are similar to the performance of Gemini, which has a context length of several million tokens.

Applications of Long-Context Large Language Models
Long-context large language models have become an important area of research and competition among leading AI labs. Anthropic’s Claude 3 supports up to 200,000 tokens, while OpenAI’s GPT-4 has a context window of 128,000 tokens.
One of the prominent advantages of large language models with infinite context is the creation of custom applications. Currently, customizing LLMs for specific applications requires techniques like fine-tuning or retrieval-augmented generation (RAG). While these techniques are very useful, they involve challenging engineering work.
Theoretically, LLMs with infinite context allow users to insert entire documents into prompts and let the model select the most relevant parts for each query. It also allows users to customize the model by providing a long string of examples to improve its performance on specific tasks without the need for fine-tuning.
However, this does not mean that infinite context will replace other techniques. It will lower the barrier to entry for applications, enabling developers and businesses to quickly prototype their applications without extensive engineering work. Enterprises need to optimize their LLM development production systems to reduce costs and improve speed and accuracy.
References:
https://venturebeat.com/ai/googles-new-technique-gives-llms-infinite-context/



